


AI Insights by Certilytics
How to Build Thousands of Clinical Predictive Models at Once: A Deep Learning Approach
How the latest advances in AI are enabling us to predict every aspect of a member’s health trajectory
SHARE IT :

Deep learning has opened new possibilities for healthcare predictive modeling, enabling us to expand our clinical risk prediction library from dozens of models to over 1,000. Our deep learning approach has vastly expanded the universe of target functions that can be modeled, meaning we can train a single model that predicts hundreds of variables representing every aspect of a member’s health profile, all integrated in a unified risk framework. This model, which we call the All CORE® Condition (ACC) Model, provides deeper insight into member and population health than ever possible before—while also making model training and deployment faster and more reliable. We can now train and deploy whole model suites as single model objects, obviating the need to manage hundreds or thousands of model SKUs.
Introduction
The fourth generation Certilytics Model Library, completed in 2023, contains 30+ clinical, financial, and behavioral models, based on our member Deep Representations (mDR), a pre-trained clinical mapping created through unsupervised learning (Dwyer et al. 2023). The Model Library is one of the central contributions of data science and machine learning to our customer solution suite, one that touches on nearly every product and feature. As such we are constantly innovating and improving the Model Library to stay ahead of the market.
For our fourth generation Model Library, we adhered to the common practice of developing one-off supervised models, e.g. separate models predicting diabetes, heart disease, stroke, and other conditions, each with different variations depending on customer data availability and requirements. As such, our machine learning infrastructure focused on training, deploying, monitoring, and updating a large number of model SKUs (Dwyer, Wright, and Tapley 2023).
One of the defining advantages of deep learning is its ability to expand the universe of target functions that can be modeled—most obviously to families of non-linear functions with composable features (Goodfellow, Bengio, and Courville 2016). But deep learning also enables us to conceive more granular—and insightful—model outputs. No longer do we need to train a new model for each target of interest, for example. We can create large networks for multitask learning, which can predict many outcomes at once, even across data modalities. This has several profound advantages:
- Greatly reducing the number of model SKUs required to build a comprehensive clinical model suite;
- Promoting parameter efficiency by allowing tasks to share weights;
- Creating a self-consistent model library in which predictions are not only based on the same shared data representations—they can also be fed forward to one another to preserve information and enforce consistency.
This is the central thesis behind the ACC Model, constituting our fifth generation model suite, which is set for a 2024 release. It is a single deep learning model that predicts 1,000+ clinical, financial, and behavioral targets. In a single stroke, the ACC Model:
- Expands our Model Library from 30+ model concepts to over 1,000, covering all clinical conditions defined by the Certilytics’ CORE® Clinical Episode Grouper;
- Improves model accuracy;
- Offers unprecedented insight into clinical drivers of model outputs, especially risk;
- Drastically reduces the labor required to train and maintain the Model Library;
- Simplifies deployment and operational scoring;
- Enhances our ability to unify clinical and financial predictions in a single framework, which we call the Opportunity Framework, thereby improving our ability to quantify the financial value of clinical interventions.
In this post, we provide a detailed overview of the ACC model. Some of these results have been shared in previous blog posts, but this is the most comprehensive discussion of design and performance to date. We also explain how this deep learning framework enables us to customize, calibrate, and even build entirely new models with unprecedented speed.
Problem
The myriad benefits of the ACC Model—spanning development, production, and product—stem from its ability to overcome several of the biggest challenges data scientists face when developing predictive models:
- The impossibly large number of model SKUs required to address the universe of clinical outcomes;
- The heavy workload associated with model monitoring, maintenance, and operations;
- The complexities involved in integrating model SKUs into a holistic risk and opportunity framework.
Indeed, the first challenge appears to pose a tradeoff with the latter two: As the number of model SKUs increases to cover more clinical outcomes, the operational and maintenance burden should grow, and it should become harder to maintain a fully integrated risk framework, where each model informs the others. Imagine having to retrain every model in a library each time a new model is added!
This tradeoff certainly exists in a traditional machine learning scenario, where individual model SKUs are trained for each outcome or target of interest. However, deep learning offers ready means to train models to multiple targets all at once. This allows a single (or small number) of model SKUs to cover increasing numbers of clinical outcomes without adding exponentially to the burden of model maintenance and integration.
Making such a complex model feasible, though, requires a novel, problem-specific deep learning architecture, a deep clinical and data-driven understanding of the set of targets and their behavior, and a data creation framework capable of handling the monumental task of organizing model-ready data for such an ambitious model.
Efficient Creation of New and Custom Models
As we will show, the ACC Model follows a design pattern we developed with the more general objective of making healthcare model training and deployment faster and more reliable. The following aspects of ACC Model design can (and will) be generalized to all Certilytics next generation models:
- The CORE® Clinical Episode Grouper data scaffold provides enormous flexibility, allowing us to model everything from claim line elements up to condition group outcomes.
- Enrichments within our model training and deployment platform, BrainstormAI®—namely documents—provide flexible, automated data representations that can be seamlessly augmented with entirely new data domains.
- Representing medical histories as documents opens healthcare machine learning to a powerful set of natural language processing and sequence modeling techniques, from RNNs to GenAI approaches like GPT.
- Deep learning architectures provide enormous flexibility in both model inputs and outputs, enabling multitask models to predict myriad events based on a shared, self-consistent representation of clinical concepts—the next generation of deep representation.
- Multitask learning, in turn, facilitates deployment. We can now train and deploy whole model suites as single model objects, obviating the need to manage hundreds or thousands of model SKUs.
- Deep learning architectures also provide incredible flexibility in customizing or calibrating models. We can freeze pre-trained portions of the network, for example, and calibrate only certain predictions heads for smaller clients with less data.
A Single Model Predicting 1,000+ Targets
ACC Model Data Structures
Like so many products and solutions at Certilytics, we began with our proprietary CORE® Clinical Episode Grouper, which organizes member claims into a complete set of clinical condition categories, along with key outcomes like cost and utilization. Then, CORE® provides the exact data creation framework necessary to build a set of hundreds of outcomes across the universe of clinical conditions to serve as targets for a holistic clinical and financial model.
For the ACC Model, we chose the following targets, tabulated over a 12 month post-period:
- Diagnosis—the presence of a CORE® condition,
- Cost—total allowed amount (Med + Rx) attributed to a condition,
- Admission—the presence or absence of an admission for a condition,
- ER visits—the presence of an ER visit for a condition,
- Surgery—the presence of surgery for a condition.
In addition to condition-level targets, member-level targets were generated for each target as well to create market standard predictions, like overall member financial risk, for a total of over 2,000 possible outcomes.
Like most Certilytics models, input to the ACC model comes in two forms:
- Member Documents representing member medical histories as variable length sequences of medical ontologies at their most granular levels (ICD-10 diagnosis codes, CPT codes, GPI codes, etc.), and
- Tabular features for the handful of structured data inputs used, like age, gender, and Social Determinants of Health (SDoH).
We note that all of these features, from inputs to targets, are readily created using CORE® and existing BrainstormAI® functionality. We have an enormous advantage designing new, more sophisticated machine learning models thanks to the clinical enrichments already present in the Certilytics data platform. Moreover, using the Member Document as the main source of model signal means we can remain extremely flexible in model design, treating entirely new input domains as a simple addition to model vocabulary.
Algorithm & Design
After much experimentation, a deep learning architecture was chosen for the ACC Model comprising (Figure 1):
- A shared embedding layer for each of the three input time periods,
- RNNs for encoding embeddings,
- Separate dense heads for each of the five outcome types,
- Predictions that are fed by other predictions in the network, e.g. diagnosis 🡪 cost,
- Member level predictions made by aggregating and feeding forward CORE-level predictions.
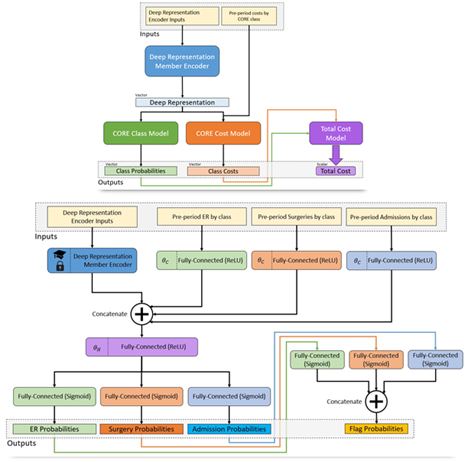
Figure 1 Architecture diagram of the ACC Model. Member histories are represented as documents and subject to a deep learning encoder, which yields a latent layer that can be used as a new member deep representation. This layer is fed in turn into a model branch predicting class probabilities for a new diagnosis of every CORE® condition (green) as well as a model branch predicting the log-transformed future cost for every condition. The resulting predictions are fed forward again into a total cost model at the member level, so the entire network can be optimized at once.
Overall, the model contains 4.8M parameters and can be trained on tens of millions of members in under an hour on our GPU infrastructure (VanMeter 2023).
Results
Much of the work of bringing an unprecedented healthcare model like ACC to production involves developing sufficient clinical, actuarial, and data science evaluation metrics and quality control. Here we present the most salient results to provide insight into model performance.
One important nuance to condition specific predictions is the difference between a predicting new diagnosis for chronic and acute conditions. It would be trivial to predict that a member already diagnosed with a chronic condition will be diagnosed again next year. For this reason, all performance metrics reported include filtering for chronic conditions, such that members are only scored if they did not have the condition in the prior period.
Figure 2 provides a visualization of the coverage of ACC model predictions mapped onto all possible targets for all possible conditions. Many of the 2,000+ possible predictions are not feasible to make, either because there are not enough examples of the target (light gray boxes) or because the model could not make them with sufficient accuracy (dark gray boxes). All told, the ACC Model makes 1,049 unique predictions across 432 conditions (Table 2).
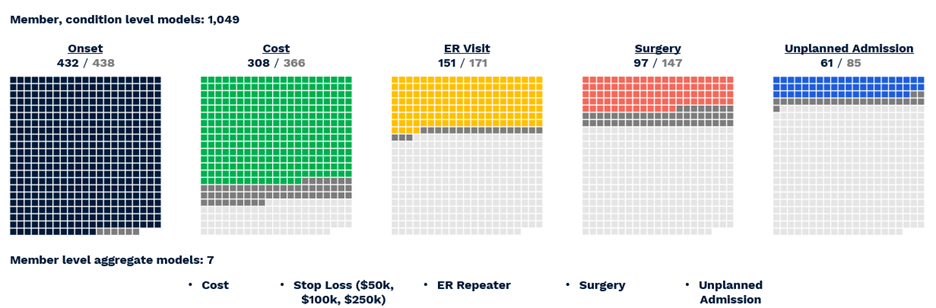
Figure 2 Visual representation of successful All-CORE model predictions. The number of production grade predictions is given as a fraction of the total number of CORE® conditions (438) which had enough prevalence for a given outcome to be modeled.
Performance can be summarized as follows (VanMeter 2023):
- Diagnosis with 432 of 438 CORE® conditions can be predicted with a C-statistic of 0.60 or greater.
- Of 366 CORE® conditions with sufficient financial data for modeling, 308 can be predicted with an R2 above 0.05, a threshold based on the performance of age/gender risk models used in the market today.
- Of 171 CORE® conditions with a sufficient prevalence of ER Visits, 151 could be predicted with a C-statistic of 0.60 or greater.
- Of 147 CORE® conditions with a sufficient prevalence of Surgery, 97 could be predicted with a C-statistic of 0.60 or greater.
- Of 85 CORE® conditions with sufficient inpatient admissions, 61 could be predicted with a C-statistic of 0.60 or greater.
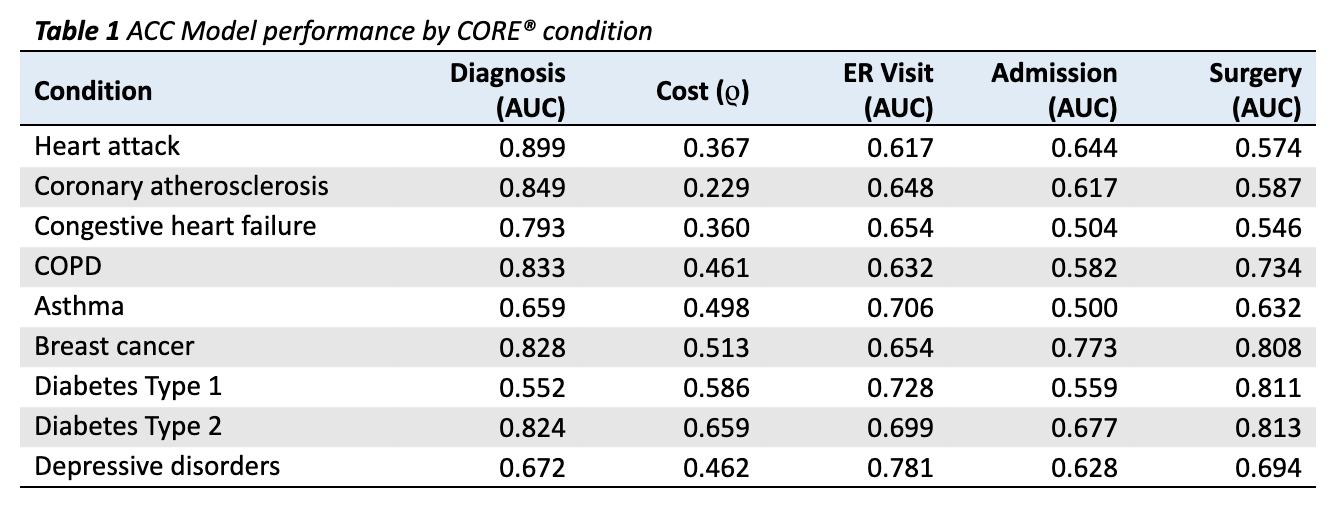
Results are given in Table 1 for 9 conditions relevant to population health management (PHM), comprising both acute and chronic durations.
- For 8 of 9 conditions, the model is able to predict onset in a naive (undiagnosed) population with an AUC above 0.60 (Table 1). The one missed condition is Diabetes Type 1, with an AUC of 0.552 (Table 1). This makes clinical sense since, unlike its Type 2 counterpart, Diabetes Type 1 is an autoimmune condition with risk factors that are poorly understood. Thus, the performance of the ACC Model begins to show an inherent clinical logic.
- To assess cost, we use Spearman’s rank correlation coefficient (ρ), which measures the extent to which the relationship between two variables can be modeled as a monotonically increasing function. In other words, can the model’s risk prediction accurately order member costs within a condition? We find the model performs well for all PHM conditions, with p-values below 0.01 for all conditions.
AUCs for ER Visits, Admissions, and Surgeries are far more variable (Table 1). This stands to reason, considering the underlying prevalence of these outcomes varies greatly by condition. For 20 of 27 possible event outcomes (three possible for each of 9 conditions), the model is able to predict the outcome with an AUC of over 0.60 (Table 1).
One major advantage of the ACC model is that these predictions, and the shared underlying latent layers on which they are built, can be fed forward to member-level predictions, which can be optimized alongside member-condition level predictions, so the whole network provides self-consistent output.
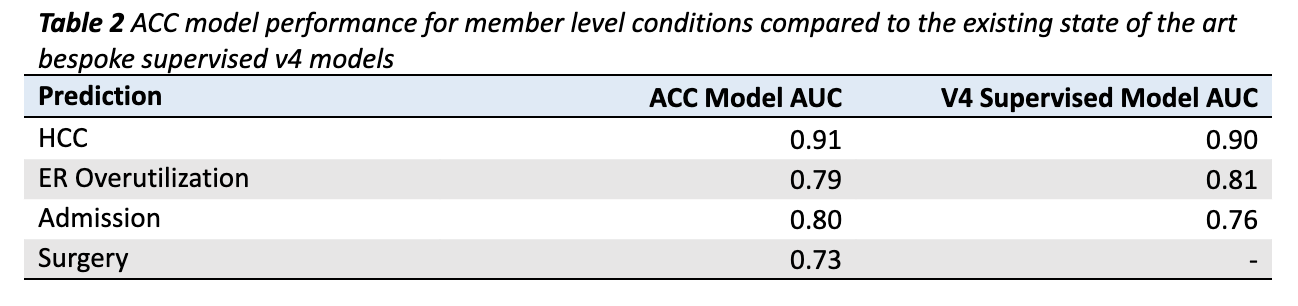
Member level results for four classification outcomes are given in Table 2. The ACC Model out-predicts existing state of the art v4 supervised models in HCC identification (AUC of 0.91 compared to 0.90) and Admissions prediction (AUC of 0.80 compared to 0.76; Table 2). The ACC Model lags the bespoke v4 model slightly in ERO prediction (AUC of 0.79 compared to 0.81; Table 2), though it is close. The surgery model has no v4 counterpart. Taken as a whole, it is remarkable that a single model trained to predict over 2,000 outcomes simultaneously performs as well or better than bespoke supervised models.
Opportunity in the ACC Model Paradigm
One of Certilytics’ foundational innovations was the Opportunity Framework, which translates modifiable risk factors on our platform into shared units denominated in dollars (Dwyer, Wright, and Saad 2023). This makes every clinical intervention or PHM program additive, accountable, and comparable. It is the only way to integrate clinical and financial analytics and allow multiple layers of stratification: stratification of next best actions within members, stratification of members within populations based on overall modifiable risk, and stratification of high level clinical opportunities and programs for a given population based on the magnitude of risk they can address.
By enabling condition-level predictions of risk and utilization, the ACC Model has enormous implications for the Opportunity Framework, enabling us to present an all-encompassing view of clinical and financial opportunities to better manage member health both across and within clinical conditions. The Opportunity Framework will now take into account predictions about more than 400 CORE® conditions, providing deeper insight into a member’s health trajectory and comorbidities. It will also include condition-specific predictions about disease progression and utilization. Using diabetes as an example, the ACC Model will allow us to answer questions such as:
- What are the top co-morbidities that a diabetic member is at risk for, and what’s the financial savings associated with avoiding those comorbidities?
- Do we expect diabetes-related ER visits, hospital admissions, or surgeries in the next 12 months, and what’s the financial savings associated with avoiding those events?
- What are the most effective treatment pathways for specific members with diabetes?
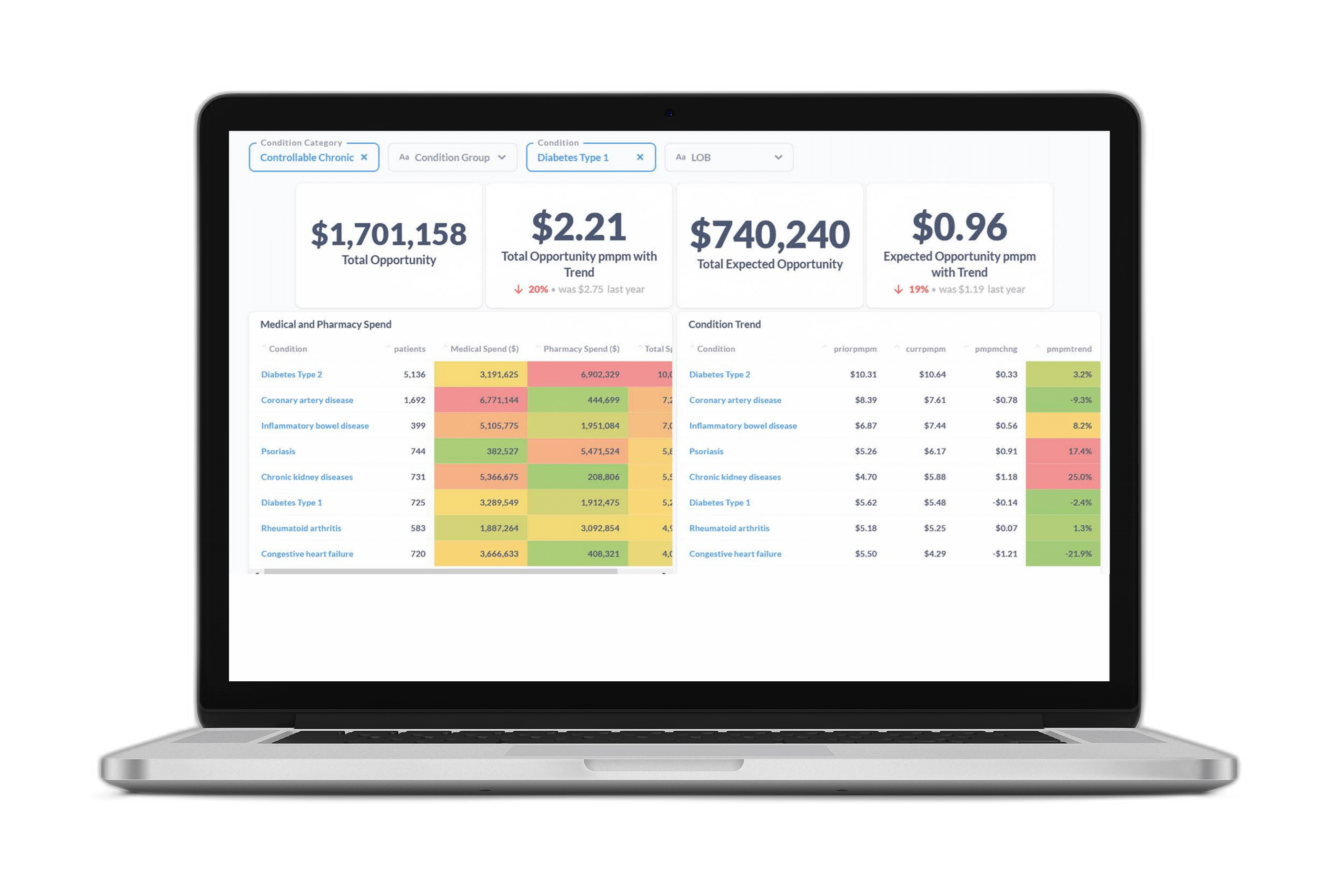
Figure 3 offers a snapshot of the opportunity profile for a sample member with diabetes. It shows diabetes-related comorbidities, events, and care gaps, along with the associated financial opportunity values. It presents a complete picture of member opportunity with granular insights to inform personalized member outreach strategies and more targeted PHM programs.
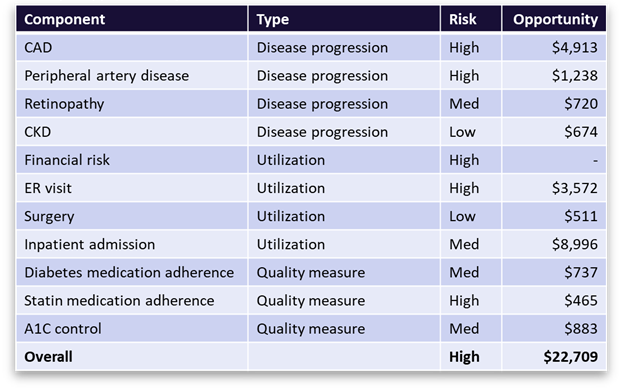
Figure 3 A breakdown of ACC Model metrics and savings opportunities for a sample member with diabetes. The table shows the top co-morbidities and high-cost events associated with diabetes that the member is at risk for, along with the financial value of avoiding those outcomes through better disease management. It also shows the open diabetes care gaps (quality measures) with the most financial value associated with closure.
References
Dwyer, Robert, Austin Wright, and Zeyana Saad. 2023. “IP Technical Documentation: The Opportunity Framework.” IP Technical Documentation. Certilytics, Inc.
Dwyer, Robert, Austin Wright, and Derek Tapley. 2023. “IP Technical Documentation, BrainstormAI® Platform.” Certilytics.
Dwyer, Robert, Austin Wright, Saad Zeyana, and Eugene Kwak. 2023. “IP Manifest, Member Deep Representations (mDR).” Certilytics.
Goodfellow, Ian, Yoshua Bengio, and Aaron Courville. 2016. Deep Learning. MIT Press.
VanMeter, Patrick. 2023. “CORE Deep Learning All-in-One Model (Model Suite V5).” Certilytics, Inc.


