



At Certilytics, we pride ourselves on our ability to extract actionable insights from medical data. Through the use of cutting edge deep learning solutions like the BrainstormAI® clinical model suite and our newly developed Deep Recurrent Embeddings for Clustering (DREC), we process millions of healthcare records daily to deliver industry-leading predictive analytics and population health management solutions.
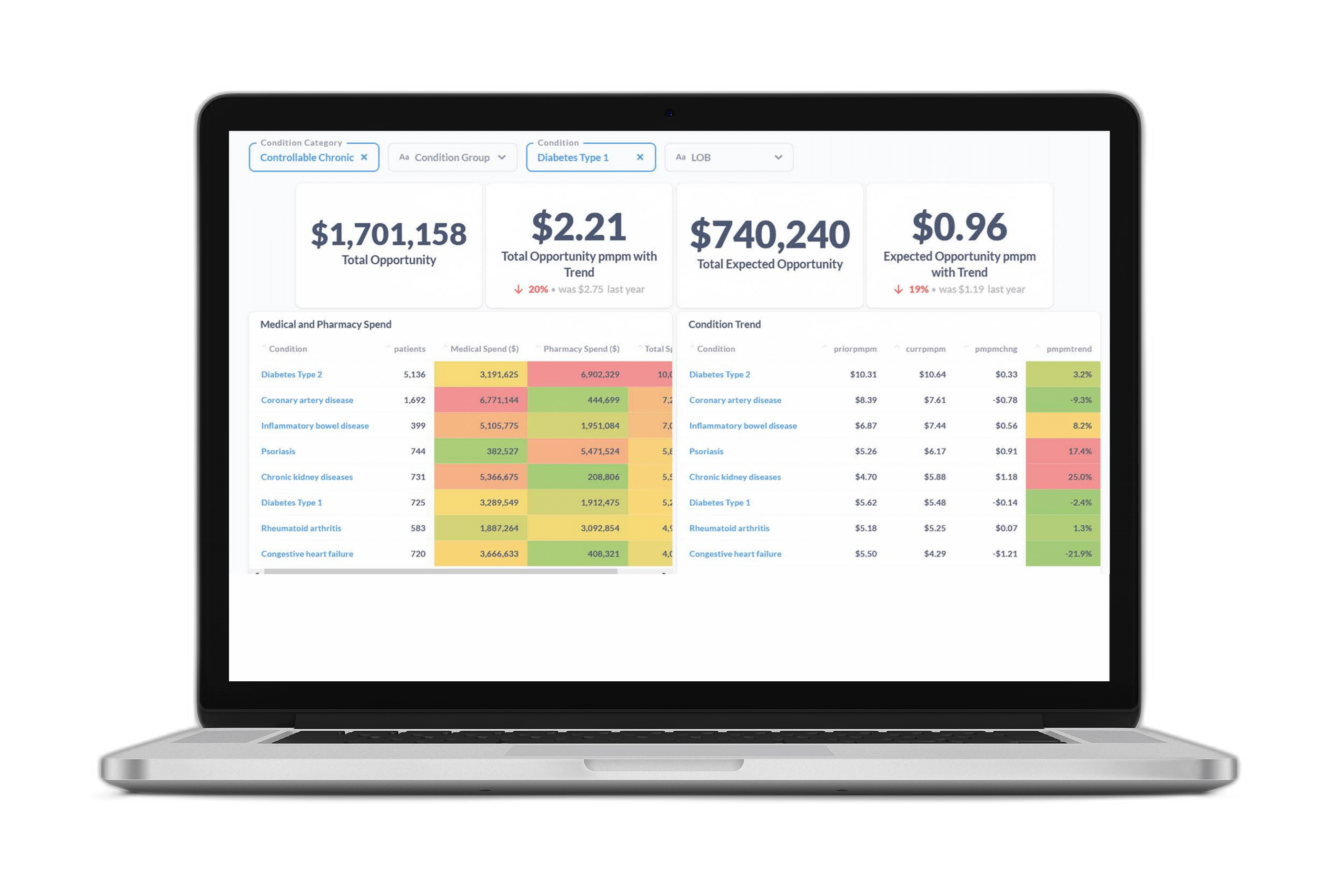
Certilytics data scientists recently launched the “Care Pathways” modeling initiative—an internal exercise to demonstrate the power of unsupervised deep learning to extract useful information from billions of data points generated from the medical claim records of over 110 million patient lives. This initiative was built around our in-house clinical episode grouper, CORE®, which allows us to effortlessly select claims associated with one of over 450 condition categories.

The team set out to discover how far we could push the use of unsupervised deep learning to generate insights into disease-specific archetypal treatment patterns, or “care pathways,” without any manual feature engineering or the introduction of a priori knowledge. This is to say our model had no conception of the differences between procedure, pharmacy, or diagnosis codes—and knew nothing of the meaning or ontology of distinct codes except what it could infer from the patterns present in the raw claims data.
Our results were striking. Using all anxiety-related medical events as determined by CORE®, the model was able to identify at least 15 treatment pathways with a clear clinical logic. It distinguished between the following conditions, among others: Generalized Anxiety Disorder (GAD); Post-Traumatic Stress Disorder (PTSD); bi-polar disorder both in diagnosis and in medication; acute admissions from outpatient treatments; and alternative medicine approaches, particularly acupuncture.
We now have the opportunity to apply this approach to dozens of other conditions. This approach allows Certilytics to understand how members within a provider network are being treated, identify treatment pattern variations, and even predict future outcomes and costs based on a member’s disease-specific treatment patterns to-date.
The Challenges of Bringing Machine Learning into Healthcare
To appreciate the significance of our results, it’s helpful to look at how predictive models are typically built and the many challenges data scientists face when attempting to design new ones.
One of the biggest hurdles to efficiently creating predictive models is the process of converting raw data from medical claims and other sources to model-ready data-sets. Doing so requires model-builders to overcome the variable-length nature of medical claims (similar to an itemized receipt) and the combinatorial complexity of billed codes (various combinations of procedures, diagnosis codes, and medications that can be billed). Ultimately, these attributes must be converted into a fixed number of model-friendly input features (covariates).
To put this complexity in context, if you were to limit the number of codes a model was capable of processing to 4,900 (just 35% of the 14,000+ diagnosis codes under ICD-9), the number of possible combinations of those codes would exceed 1×101475. With the move to ICD-10, that same 35% jumps to almost 23,800 codes. The number of possible combinations in that subset exceeds the estimated number of atoms in the universe [1]. Fold in procedure codes (70,000 unique codes), medications, provider information, and additional data points that may be present in a claim—and the number of possible combinations is essentially limitless.
As a result, most of this information is not yet used in the sorts of predictive statistical models that might allow health plans and providers to improve patient outcomes, cost of care, and network creation.
Traditionally, data scientists and statisticians have dealt with this complexity simply by choosing a limited number of well understood variables to consider. This variable creation process usually entails carefully crafted business rules and manual feature engineering on a model-by-model basis. Each new model, based on the input of data scientists, clinicians, and business leaders, may require hundreds or even thousands of these manually defined features [2].
Payers and providers are increasingly looking to expand the number of conditions and outcomes they monitor in an effort to minimize waste and growth in their healthcare spend, yet this data-set preprocessing, merging, customizing, and cleaning typically accounts for 80% of the effort associated with an analytic model [3,4], profoundly limiting the scalability of these predictive tools. The development of each new model is a massive investment, and usually takes many months to go from concept to production.
Recent advances in deep learning have laid the groundwork for algorithms that can effectively learn from raw data, bypassing the need for manual feature extraction and selection. One such popular method, which learns powerful representations of the data automatically, is an autoencoder. Autoencoders effectively seek to learn the intrinsic structure of the data with a deep neural network, and do so by learning to reconstruct the original data, regularized via a bottleneck, inducing a compressed representation. This learned representation of the raw data is then typically used in a range of tasks, such as an input to a supervised model (where we know the outcome we are trying to predict) or an unsupervised model (where the outcome is unknown).
Certilytics’ Model
To accomplish our goal of identifying archetypal treatment patterns, we developed a novel framework, Deep Recurrent Embeddings for Clustering (DREC), by combining an auto-encoder with a clustering algorithm into a single, end-to-end modeling pipeline. This framework was designed to overcome specific limitations, namely the need for predefined features, traditional machine learning models’ inability to handle variable length inputs, and the impossibility of knowing the correct number of treatment pathways in advance. Any discernible clinical distinctions among classes indicated the model had identified meaningful signal.
As a way to validate our exercise, a 12-month retrospective cost model was trained on a subset of patients with at least 12 months of claims data, using our BrainstormAI® machine learning platform. A count vectorized representation of the different treatment patterns identified by our DREC algorithm outperformed a one-hot encoding of the full feature space (6,445 features) and a model based on only the top 100 most important features when using ordinary least squares (OLS) regression. To summarize, this meant that our 25 features, generated in a fully unsupervised fashion, were better at predicting retrospective cost despite a compression ratio of over 99.6%.
To learn more about Certilytics’ propriety algorithms and predictive models—and how Certilytics can help you see the future through data—contact us.
Works Cited:
1) Kini, P. ICD-10 and Combinatorial complexity. Available at: https://www.beckershospitalreview.com/healthcare-information-technology/icd-10-and-combinatorial-complexity.html
2) Press, G. Cleaning big data: most time-consuming, least enjoyable data science task, survey says. Forbes (2016). Available at: https://www.forbes.com/sites/gilpress/2016/03/23/data-preparation-most-time-consuming-least-enjoyable-data-science-task-survey-says/
3) Lohr, S. For Big-Data Scientists, ‘Janitor Work’ Is Key Hurdle to Insights. Available at: https://www.nytimes.com/2014/08/18/technology/for-big-data-scientists-hurdle-to-insights-is-janitor-work.html
4) Goldstein, B. A., Navar, A. M., Pencina, M. J. & Ioannidis, J. P. A. Opportunities and challenges in developing risk prediction models with electronic health records data: a systematic review. J. Am. Med. Inform. Assoc. 24, 198–208 (2017).


